Trust and Safety at Meta
The Meta Trust and Safety page introduces their approach to trust and safety. At the same time as the recent release of Meta Llama 3, they released Llama Guard 2, Llama Code Shield, and Llama CyberSec Eval 2 open-source tools. These tools are used in the stages of AI product development as shown in Figure 2.
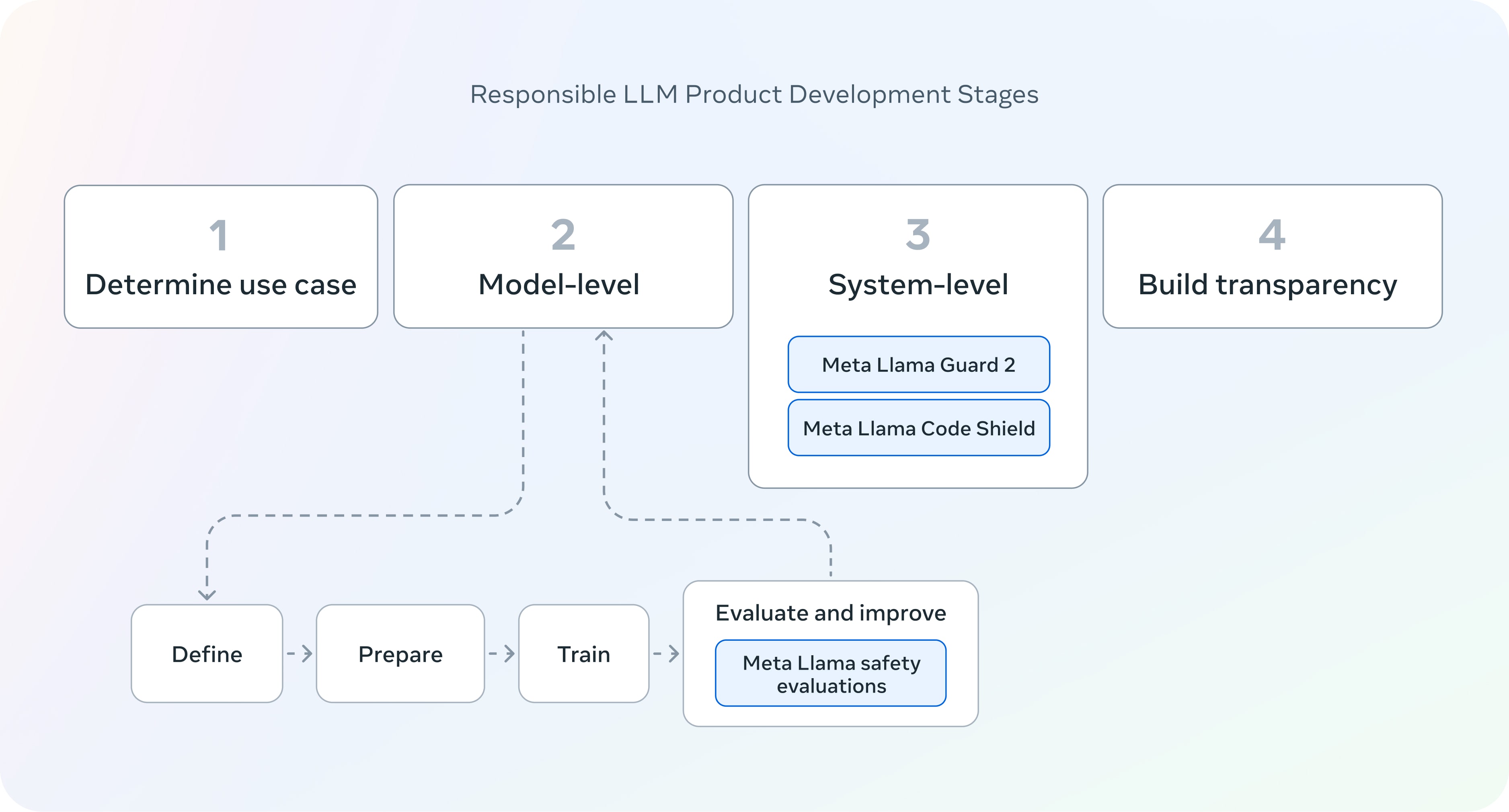
Figure 2: Responsible AI Product development stages and where the Meta Llama tools fit in. (Source: Meta Trust and Safety)
Note the importance of mitigating risk at the system level, as well as model level mitigation. The latter is important, but not sufficient.
Meta Llama CyberSec Eval 2 performs model-level evaluations. It addresses the following potential vulnerabilities:
- Insecure code practices: For code generation and autocomplete, ensure no known vulnerabilities are inserted, based on the Common Weakness Enumeration standard taxonomy, coordinated by Mitre.
- Cyber attacker helpfulness: Contains tests that a) measure an LLM’s propensity to help carry out cyberattacks as defined in the industry standard MITRE Enterprise ATT&CK ontology of cyberattack methods and b) measure the false rejection rate of confusingly benign Prompts.
- Code interpreter abuse: Code interpreters connected to LLMs allow the latter to run code in a sandboxed environment. This evaluation detects attempts to run malicious code.
- Offensive cybersecurity capabilities: While simulating program exploitation, can the tool reach a specific point in a test program where a security issue has been intentionally inserted? For example, can the tool execute exploits such as SQL injections and buffer overflows?
- Susceptibility to prompt injection: The prompt Injection tests evaluate the ability to recognize which part of an input is untrusted and the level of resilience against common prompt injection techniques.
AI System-level safeguards are provided by Meta Llama Guard 2 and Meta Llama Code Shield. Meta Llama Guard 2 (model card, model download) is a model trained to detect objectionable content based on the taxonomy of hazards recently published as part of the MLCommons AI Safety v0.5 Proof of Concept, which we discuss in more detail below. Meta emphasizes that this model is a starting point rather than a universal solution. Meta Llama Code Shield (sample workflow) is a new tool for filtering insecure generated code at inference time. The Llama Github repo has an example implementation of these Guardrails.
These tools, along with how they fit into the product development process, support the practices in Meta’s Responsible Use Guide, which provides guidance for building AI products responsibly at every stage of development and every part of an LLM-powered product. It provides guidance on understanding the context of your specific use case and market, as well as mitigation strategies and resources for addressing risks.
Responsible AI considerations include fairness and inclusion, robustness and safety, privacy and security, transparency and control, as well as mechanisms for governance and accountability. (It’s not surprising that we encountered similar considerations while discussing NIST’s Risk Management Framework.) LLMs and other AI tools need to be evaluated according to these considerations in the context of how the tools will be used.
Meta’s own AI-based applications integrate detection and mitigation of risks at the most appropriate intervention points. For example, they found during development of Llama 2 that mitigations applied too soon in the development process proved detrimental to performance and safety of the resulting models. They explored appropriate points in the model development life cycle for the most effective application of interventions. In general, developers need to balance various tradeoffs to find the best points in their development processes and application stacks for particular risk mitigations. Holistic analysis is required, too, as mitigations in one place can impact behaviors elsewhere.
Most of Meta’s Responsible Use Guide discusses the whole software development process for AI applications, designed to maximize safety and alignment of your AI systems for its goals. We return to this subject in Safety for Your AI Systems.
The next section explores Mozilla Foundation’s guidance on Trustworthy AI.