The Evaluation Reference Stack
Part of the AI Alliance Trust and Safety Evaluation Initiative (TSEI), our goal is to create the world’s most comprehensive and useful tool set and resources for anyone seeking to benchmark, evaluate, and monitor AI systems. Welcome to the Evaluation Reference Stack project, a foundation of that effort, to provide a de-facto standard, easy-to-use platform to run evaluations of all kinds.
Tip: The links for italicized terms go to this glossary.
There are many open-source and commercial frameworks for AI evaluation, for example to detect hate speech and hallucination, to measure the question-answering abilities, etc. However, there are no real standards which are widely used by implementers, so that most evaluation suites require separate tools. Some suites and corresponding tools are better engineered for research purposes, while others are suitable for production deployments.
This project is identifying and endorsing evaluation tools that are already widely used, with the potential to become industry standards. These tools address the varied needs of both creators (researchers and system builders), as well as consumers of evaluations. Ideally, an evaluation platform supports offline use, such as for benchmarks and related testing purposes, as well as online use, during inference and agent flows, where support is required for production-quality concerns, such as scalability and robustness.
Our goal is to enable enterprise developers, who are usually not evaluation experts, to quickly and easily deploy the runtime stack they need for executing evaluations online or offline. The companion AI Alliance projects, Evaluation Is for Everyone and Testing Generative AI Applications focus on defining the evaluations themselves (e.g., for hate speech, hallucinations, etc.), which are deployed on the reference stack.
Figure 1 shows the relationship between these projects.
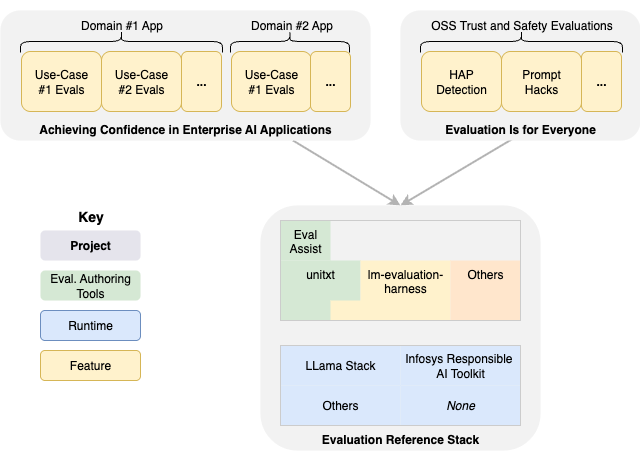
Figure 1: The reference stack in context.
Note that the evaluation reference stack runs the evaluations that come from the other two projects.
Specifically, Evaluation Is for Everyone is aimed at making it easy for developers to find and deploy the AI trust and safety evaluations they need, analogous to how cybersecurity capabilities must be included in all modern applications. The appropriate set of evaluations would run on the reference stack.
Similarly, Testing Generative AI Applications addresses a current gap in AI-enabled application development; how to test that the applications behave as designed, when generative AI models are inherently probabilistic, instead of deterministic. The same evaluation tools AI experts use to evaluate models for trust and safety concerns can be applied to this problem. In other words, custom evaluations need to be written that test individual use cases and related requirements, and integrated into familiar test suites. In part, the confidence project will help educate developers on how to use these tools effectively in combination with the testing and quality assurance (QA) tools they already use.
Figure 1 also shows several possible components in the reference stack. We dive into the details in Reference Stack Details.
Getting Involved
Are you interested in contributing? If so, please see the Contributing page for information on how you can get involved. See the About Us page for more details about this project and the AI Alliance.
Additional Links
- The project’s GitHub repo
- Companion projects:
- The AI Alliance: