Simplify GenAI RAG Deployments with Open Platform for Enterprise (OPEA)
Chatbots are often considered canonical examples of generative AI (GenAI) because they encapsulate several core principles and capabilities of this technology. Chatbots leverage GenAI to understand and generate human-like responses in natural language. This involves interpreting user inputs, processing the previous interactions, and producing coherent, relevant replies. Chatbots can maintain a conversation across multiple turns, understanding the context and responding appropriately. This showcases the generative model’s ability to handle dynamic, real-world communication scenarios. Generative AI enables chatbots to tailor responses based on user preferences, past interactions, and specific needs. This personalization is a key feature of generative models, making them more effective in user engagement. Large Language Models (LLMs) offer these capabilities to varying extents. So a chatbot backed by an LLM is a powerful tool that can interact with users in a highly nuanced pre-trained context-aware manner. These chatbots, powered by LLMs, are capable of understanding complex queries, providing detailed responses, and even handling ambiguous or open-ended questions. The generative nature of LLMs allows these chatbots to not only retrieve information but also create new content on the fly, making the interaction more dynamic and personalized. However, it presents some challenges. Hallucinations can occur when the model generates plausible but incorrect information. Ensuring accuracy, managing content relevance, and addressing the potential for outdated responses are critical issues that need to be addressed when deploying these models.
Retrieval-Augmented Generation (RAG) architecture is quickly becoming the industry standard in chatbot development. This architecture combines a knowledge base (via a vector store) with generative models to reduce hallucinations, maintain up-to-date information, and leverage domain-specific knowledge. RAG bridges the knowledge gap by dynamically fetching relevant information from different sources, ensuring that the responses generated are both accurate and up-to-date. However, implementing a RAG system involves coordinating multiple components, which poses challenges, especially when deploying at an enterprise scale, where data security, scalability, and infrastructure integration are critical.
OPEA, the Open Platform for Enterprise AI, is a project with the Linux Foundation AI & Data. It provides a framework of composable microservices for state-of-the-art GenAI systems including LLMs, data stores, and prompt engines. Additionally, OPEA provides several RAG blueprints, currently >10 implementations and growing, for end-to-end workflows including popular use cases like VisualQnA, CodeGen, and RAG systems(ChatQnA). OPEA applications leverage cloud-native architecture to simplify deployment, including a friendly high-level pipeline, based on the definition outlined in the white paper published by the CNCF AI Working Group’s, providing a language for a fully containerized deployment on Kubernetes.
OPEA treats each component in the RAG pipeline as a modular building block, ensuring easy interchangeability and customization. Say, for example, you’re using an LLM like Mistral, but want to easily replace it with Falcon. Or, say you want to replace a vector database on the fly. You don’t want to have to rebuild the entire application. That would be a nightmare. OPEA makes experimentation and deployment easy by providing robust tools and frameworks for seamless integration across platforms.
ChatQnA Reference Architecture
Among the multiple examples OPEA provides to help with deployments of GenAI applications (CodeGen or VisualQnA), we will explore the RAG chatbot (ChatQnA) as a prototypical example, composed of several independent modules, each tightly coordinated to handle specific functions or tasks, as shown in the image:
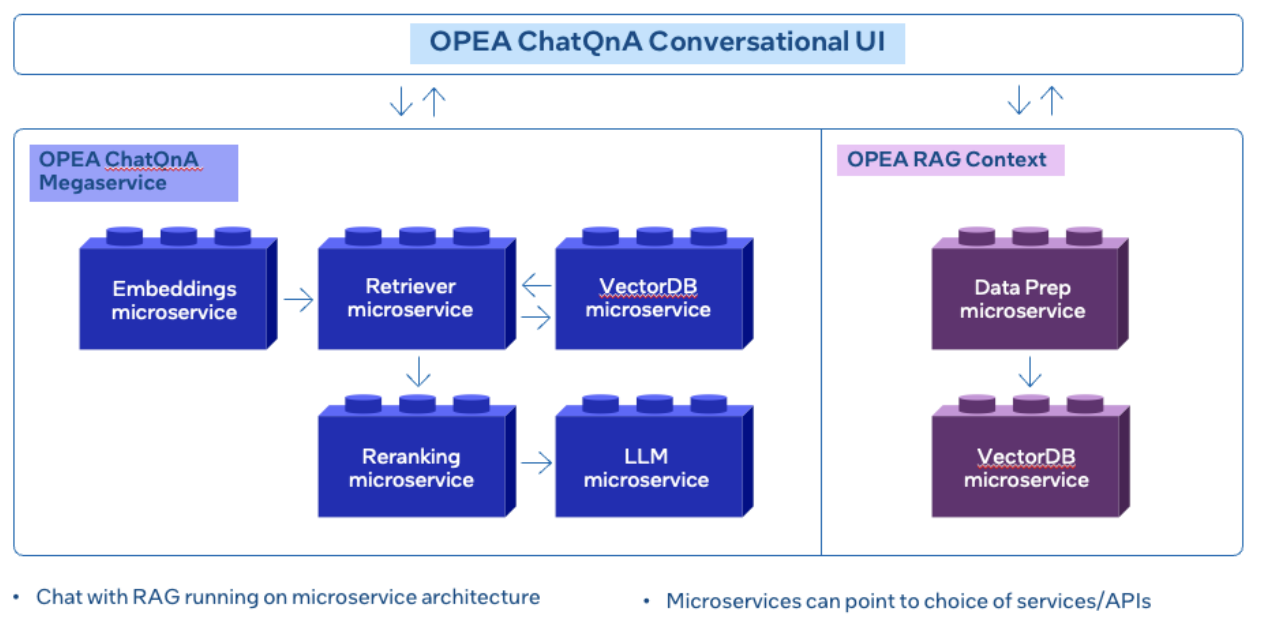 The reference architecture is divided into 3 parts:
The reference architecture is divided into 3 parts:
-
Conversational UI: The chatbot interface includes an input field for user queries, which displays responses and passes the user inputs to the backend (Megaservice) or RAG context.
-
ChatQnA Megaservice: This group of microservices receives the user message from the UI and starts the RAG process. The megaservice is a higher-level construct that assembles multiple microservices (retriever, embeddings, reranking, LLM) to deliver end-to-end applications. Unlike microservices, which handle specific tasks, this megaservice will orchestrate the microservices’ interactions to provide a complete solution, encapsulating complex business logic and workflows. This modular approach integrates microservices as a unit to fulfill specific application requirements.
-
RAG Context: The example allows the user to upload a file to be used as context for future queries. The dataprep microservice performs the preprocessing and inserts it into the vector database to be used to provide context for future queries. Each microservice is available as a Docker container. This allows any GenAI example to be deployed using Docker Compose or a Kubernetes cluster.
Call to Action
Try building your chatbot using the ChatQnA demo following the steps from the repository:
- Start docker service using docker image
- Pull pre-built docker images from docker hub
- Build microservices from source
- Set environment variables
- Deploy end-to-end example (docker compose or Kubernetes using Helm Chart)
- Consume individual microservices / megaservice
- Monitoring with Prometheus and Grafana dashboard
Conclusion
Thanks to the modularity offered by OPEA, any block in this example can be easily replaced without the need to rebuild the entire setup, allowing both experimentation for tuning performance and outcomes, and then enabling ease in productization on existing infrastructure.
You can navigate to the GenAIComps repo, where all components are hosted, and build your example using any of the available microservices contributed by partners and the community that is part of OPEA. For example, you can swap out the vector store (redis) used in the example with any of the other available options such as Chroma, Milvus, pgvector, pinecone or qdrant.
Follow the recipes of each docker repository to see how the docker compose files are built and replace the microservices with those you can find on the components repository (GenAIComps).
Visit OPEA on GitHub to learn more about the project. Follow on LinkedIn, or Join the Wiki.