Notes on Tuning
Table of contents
This chapter contains notes on various Tuning techniques, including those use by foundation model builders who have broader goals than the incremental refinement tuning that interest us in this guide. Hence, not all the techniques and ideas discussed here will be important for our purposes.
WARNING:
These are raw notes. They are not very well organized, but if you are interested in the state of the art for model tuning, these notes provide a good place to start, with plenty of links to more advanced materials. Eventually, these notes will be refined and incorporated into other chapters, especially From Testing to Tuning.
Highlights:
- Tuning has different meanings and goals for different people, which determines the best techniques to use, along with different data and compute requirements.
- For model builders, tuning means taking a raw model and making it better at general instruction following, adherence to social norms, etc. This task requires the largest data sets and most sophisticated, leading-edge techniques.
- For end users building apps, tuning means taking one of those tuned models and further tuning it for domain-specific behaviors, etc. This task requires much smaller data sets, although they will need to be more specialized for the domain-specific behaviors, and more straightforward tuning techniques, such as Supervised Fine Tuning.
- Hugging Face’s a smol course is recommended for learning about tuning techniques. Their LLM Course is recommended for a general introduction to LLMs.
Hugging Face Training on Model Tuning
Hugging Face’s a smol course is designed to teach all aspects of model Tuning. It is not yet complete, but projected to be done by the end of 2025.
Some of the modules, like for instruction tuning are more relevant when tuning “raw” base models to be better at instruction following, aligned with social norms, etc. For domain-specific tuning, such as we discuss in From Testing to Tuning, you would normally start with a model that is already instruction tuned and proceed from there.
TIP:
This is the best place to start for practical training on tuning.
Also recommended is their more general LLM Course, which provides useful background information that is assumed by the smol course.
“How to approach post-training for AI applications” - Nathan Lamb0
This section summarizes of Nathan Lambert’s NeurIPS 2024 talk, How to approach post-training for AI applications (December 10, 2024), along with the following supporting blog posts and other links that are referenced in the presentation and listed here in reverse chronological order. Some terms in this list will be defined later:
- OpenAI’s Reinforcement Finetuning and RL for the masses (December 11, 2024) - A description of OpenAI’s recently announced research program combining RL and fine tuning (our spelling here). There is a link in the post to an OpenAI web page for this, but it appears to be gone now.
- SimPO: A New Way to Teach AI Models to Follow Human Preferences (December 2, 2024) - Another replacement for RLHF that provides very efficient and effective fine tuning of instruction models.
- OpenAI’s Strawberry, LM self-talk, inference scaling laws, and spending more on inference (September 6, 2024) - Details on inference scaling laws and uses of it to improve inference.
- A recipe for frontier model post-training (August 07, 2024), which discusses the general topic of state-of-the-art Post-Training a Pre-trained model.
- Do we need RL for RLHF? (December 6, 2023) - “Direct (DPO) vs. RL methods for preferences, more RLHF models, and hard truths in open RLHF work. We have more questions than answers.”
- RLHF progress: Scaling DPO to 70B, DPO vs PPO update, Tülu 2, Zephyr-β, meaningful evaluation, data contamination (November 22nd, 2023)
I put in the dates, because everything is moving rapidly and it helps to know the sequence of these writings, as some of the ideas discussed emerged after a particular post was written.
Incidentally, Nathan also co-presented a tutorial on language modeling at the same NeurIPS conference.
Nathan also has a new book on Reinforcement Learning with Human Feedback (RLHF).
Introduction
As the presentation points out: The raw pre-trained LMs are neither safe nor robust for public use and interactions, thus require “alignment” between AI and humans.
Where the terms are as follows
- Pre-Training creates the raw LLM.
- Adaptation is the process for Alignment, so that the resulting model is better in the following ways:
- It follows natural language instructions better.
- It is aware of harmful behaviors.
- It responds according to human preferences.
- It has improved core skills.
In the blog post, A recipe for frontier model post-training, he mentions that some seminal projects on adaptation, InstructGPT, WebGPT, Sparrow, Summarizing from Human Feedback, and Helpful and Harmless Assistant are becoming out of date with how tuning, especially with Reinforcement Learning with Human Feedback (RLHF), is done today. While the goals, high-level tools, and some of the evaluations are still relevant the details of data curation and other aspects are now dated.
He cites the Llama 3.1 paper, an Apple paper (arXiv), and others as more up-to-date descriptions.
The new recipe these projects use requires a few assumptions to hold:
- Synthetic data can be of higher quality than humans, especially for demonstrations on challenging tasks.
- Reinforcement learning from human feedback (RLHF) can scale far further than instruction tuning.
- It takes multiple rounds of training and generation to reach your best model.
- Data filtering is the most important part of training.
The New Standard Pipeline
This section summarizes part of the blog post, A recipe for frontier model post-training.
1. Human Preference Data
Nathan says the focus of the original RLHF pipeline was on human data, which came in two primary forms: 1) human data for instruction-tuning on specialized tasks and 2) human preference data on model completions. The data sets were costly to create with few OSS data sets available. Also, while he was at Hugging Face, his team found that success tuning one model didn’t always translate to success tuning other models.
These days, the only human-generated data widely used appears to be preference data, used for Instruction Fine Tuning (IFT) (the most common form of Supervised Fine Tuning - SFT). Human-generated data is expensive to acquire. Based on what information is available about Llama 2’s training, Nathan speculates that Meta spent at least $10-20 million on preference data. In contrast, Nemotron was developed with a large amount of synthetic data to replace the human data, but the model is not considered comparably strong.
Because of the expense of human data, there is a need and therefore an opportunity for the open community to pioneer reducing human input with LLM-as-a-judge or reward modeling techniques (the latter for reinforcement learning).
2. Scaling RLHF
Reinforcement Learning with Human Feedback (RLHF) is considered by many researchers to be more scalable and more productive than instruction fine tuning, so much so that many model builders may stop using IFT. At the very least, the current consensus is to use IFT initially, especially for domain-specific tuning, then switch to RLHF.
RLHF is an iterative process of refinement, with each model generation improving over its predecessor. An open question is how many rounds are optimal. The Llama 2 paper and the Nemotron paper detail about five training rounds. Llama 3.1 used six rounds and Nemotron used four. Multiple instruction tuning rounds were done before these RLHF rounds.
There are two practical reasons for using iterations like this:
- The third-party annotation companies supplied the human data in batches, rather than all at once, so they did tuning iterations with the data that was available.
- In general, iterations are a universally-wise strategy. They de-risk any project, since you can check progress as you go to be sure you are moving in the right direction, rather than waiting for all data to be available and doing one large and expensive training run with an uncertain outcome.
The Llama 2 paper has diagrams (reproduced in the presentation) that show how the model’s harmlessness improved during several iterations of RLHF tuning.
The algorithms used for RL (or replacing it…) have evolved rapidly, with several popular variants in use. For example:
- Proximal Policy Optimization (PPO) - An algorithm for training a reward model used in RL that eliminates stability problems and some overhead of earlier algorithms. Used widely by OpenAI since 2018, at least until recently.
- Direct Preference Optimization (DPO) - The most popular algorithm currently, which is simpler to use and more stable than PPO. It eliminates the need for a reward model and hence the use of “classical” RL. Instead a preference data set is used to tune the target model directly, whereas in PPO, the data is used to train the reward model, which is then used in an RL process to tune the target model.
- MDLOO used by Apple and based on research from Cohere.
See this blog post for an accessible overview of DPO. The following image is taken from and explained in that post:
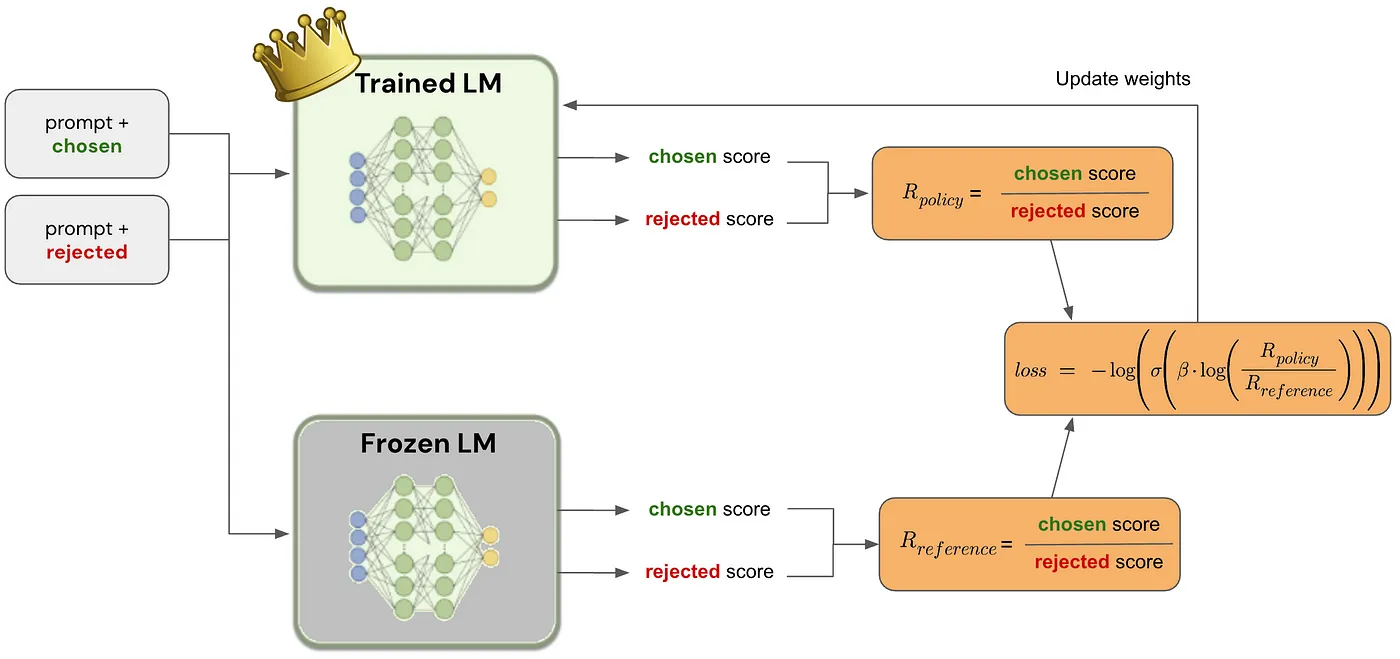
I won’t repeat the explanation here…
See also:
- An Interconnects post Do we need RL for RLHF?
- An Ai2 video on DPO.
- Unsloth documentation on different RL algorithms.
- Sebastian Raschka’s detailed description of RLHF published two years ago, shortly before DPO came out.
3. Synthetic Data
Because of the expense of human generated or curated data, synthesizing data is now an established part of tuning. One very common practice is to use bigger models to generate data used to tune smaller models.
From the Discussions section of the slides, How much data do you need?
- For instruction fine tuning:
- You can start to see behaviors change with just ~1000 samples.
- For good performance, you need data on each task you are trying to improve.
- Performance continues to improve as you scale the data per task, even when approaching millions of examples.
- For RL fine tuning:
- OpenAI says performance improves with just ~10 samples. This is just for entirely out-of-distribution tasks.
- In work on Ai2’s in Tülu 3, performance continued to scale with 100s to 1000s of examples.
In contrast, if you are doing full post-training, by which I think he means full in the sense of a raw foundation model being tuned for widely varying applications, you should expect to use:
- 1 million+ SFT prompts.
- 1 million+ preference pairs.
- Substantial data filtering.
Obviously the narrower the application or domain being targeted, the less expensive it will be to acquire enough data for good results.
4. Data Quality Is King
“The majority of the Llama 3.1 report is about data curation details.” High-quality, domain-specific data is essential to successfully tune a domain-specific model.
Putting It Together
Here is a diagram of the Llama 3 tuning process taken from the Llama 3 research paper:

A similar process was used for Nemotron.
Side Note: What Is Rejection Sampling?
Rejection sampling is a technique for randomly sampling data points weighted by a probability distribution. For example, consider the blue normal distribution curve in this diagram from Wikipedia.

Now suppose you want to randomly sample x values between -5 and +5, where the resulting set should have more values near the mean of a normal distribution, which is x=0, and fewer values away from the mean, that is where the density of x values corresponds to the distribution.
To do this randomly pick (x, y) points on the diagram, then reject those where the y value is above the curve. Keep the “surviving” x values. In the resulting set, the x values will be denser near the mean, etc., following the distribution.
Apple Confirms the New Normal
In the blog post, A recipe for frontier model post-training, he discusses how Apple also followed the same general recipe for its models, with some interesting points of difference:
- For initial instruction tuning, they treated it as an optimization process, where they explored the optimal mix of instruction data sets to use.
- They found that the best instruction base model doesn’t always lead to the best model after RL.
- Their rejection sampling technique, called iTeC uses a large “committee” of models to generate completions, where the best completion per prompt is chosen.
- The used an RL algorithm called MDLOO based on research from Cohere.
It’s not mentioned in the blog post, but the Apple paper’s section 5.1, Adapter Architecture, discusses dynamic use of LoRA to fine tune their models for user’s everyday activities. This could be interesting for the ideas discussed in From Testing to Tuning, where we need the ability to incrementally tune models as features are added to applications.
The Presentation’s “Discussion” Section
Back to the presentation’s Discussion section. Most of this material will be relevant for advanced tuning situations, like improving raw base models. Below are notes on the incremental, pragmatic approach we will start in our work. This section starts with slides on data requirements, which I worked into sections above.
What Techniques Should You Use?
On the slide titled What post-training methods should you use?, he suggests this:
- Use instruction tuning / SFT for improved behavior control and performance gains.
- Use preference tuning / PreFT for stronger style control, but it’s not as useful for improving performance.
- Use RL tuning for the potentially very high performance gains, but this remains unstudied.
Comparing DPO and PPO
Next, Nathan points out that “DPO and PPO are very different optimizers:”
- DPO is learning directly from preferences vs. using RL update rules.
- DPO is also not really online vs offline RL, but that is more muddled.
It’s not yet clear if one is truly superior to the other. Early experience suggests each approach may be optimal in particular cases. See this post from Nathan, The DPO Debate and his video explainer.
Other Algorithms
GRPO
Group Relative Policy Optimization (GRPO), introduced in the DeepSeekMath paper is explained concisely in this DataCamp blog post, which also compares it to PPO and DPO. It has the advantage that it doesn’t require labeled data, just a means to “verify” correctness and order responses accordingly. For example, to train model to generate source code, a reward function can be used that verifies the generated source code compiles, passes tests, etc.
In the typical GRPO workflow, the model generates several outputs, the reward function rates each one, and the model weights are updated to favor future generation of the better results.
This method is data and cost efficient, less likely to over fit, and promotes learning novel strategies and chains of thought.
Some example domains where GRPO has been used:
- Mathematical skills
- Code generation
- Multi-step reasoning
KTO
Yet another algorithm has emerged, Kahneman-Tversky Optimization (KTO), which only needs directional labels on one completion rather than pairwise data. So, if you collect data that is only 👍 or 👎, KTO is very promising and is often more aligned to a particular problem’s specification. Anecdotally, Nathan has heard of several cases where people have switched from DPO to KTO and see improvements. However, there is little research to base this on.
SimPO
Another alternative to DPO is SimPO: A New Way to Teach AI Models to Follow Human Preferences (December 2, 2024) - Another replacement for RLHF that provides very efficient and effective fine tuning of instruction models.
Which Base Model?
Should you start with a base model or an instruct model as your foundation?
- For small changes → start from an instruct model.
- for developing many capabilities or for bigger changes → start from a base model.
Deciding on the foundation model to use:
- Performance variations (and ceilings): Some models will show better behaviors for different different tasks! Consider trying multiple options, e.g. Mistral Large is great for CLIs.
- Implementation variations: If you are building open-source models, some also have wildly different behavior in open source tools (e.g. Qwen 7B faster than Phi 3B in vLLM due to implementation issues).
What About Effective Use of Prompting?
Every frontier lab extensively uses prompting to help target specific behaviors for specific evaluations. You will have to figure out how this applies to your domain.
How to Use Inference Scaling Laws
The intuition of inference scaling laws is based on the observation that if your model CAN generate the correct answer sometimes, then scaling inference up can make that more reliable. It is also expected that future inference-scaled training will learn new behaviors. I believe this reflects the fact that more expensive models, where you pay more per token generated, tend to produce better results. It appears this also applies for pre- and post-training, even if inference costs were fixed. Spending more money per token gives better results.
Nathan goes into this in more detail in his post OpenAI’s Strawberry, LM self-talk, inference scaling laws, and spending more on inference.
Reinforcement Fine Tuning
Back to Nathan’s NeurIPS 2024 presentation, which was published four months after the blog post, he discusses OpenAI’s recently announced RL approach called Reinforcement Fine Tuning1 (RFT), which is described in this OpenAI page (no longer online!). He also discusses RFT in this Interconnects post.
Here is a description of RFT adapted from the presentation:
What Is Reinforcement Fine Tuning?
Reinforcement fine tuning uses repeated passes over the data with reinforcement learning (RL) to encourage the model to figure out more robust behaviors in domains.
It requires:
- Training data with explicitly correct answers.
- A grader (or extraction program) for verifying outputs.
- A model that can sometimes generate a correct solution. Otherwise, there will be no signal for RL to learn from.
Key innovation:
It improves targeted skills reliably without degradation on other tasks.
RFT has since been launched as a product feature by OpenAI and it appears they have published very little about it themselves, since the initial web page disappeared. See this independent post on how to use the product feature. If OpenAI is successful with their product offering, it will greatly increase the available domain-specific tuned models.
RFT is entirely focused on conventional model tuning, but it may fit our goals of finding general ways to assure desired behavior in an incremental fashion. In fact, this paper, Reinforcement Fine-Tuning Naturally Mitigates Forgetting in Continual Post-Training, compares SFT and RFT, finding the latter superior for avoiding catastrophic forgetting, especially in the context of continual fine tuning. Here is the abstract for that paper:
Continual post-training (CPT) is a popular and effective technique for adapting foundation models like multimodal large language models to specific and ever-evolving downstream tasks. While existing research has primarily concentrated on methods like data replay, model expansion, or parameter regularization, the fundamental role of the learning paradigm within CPT remains largely unexplored. This paper presents a comparative analysis of two core post-training paradigms: supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT), investigating their respective impacts on knowledge retention during CPT. Our experiments are conducted on a benchmark comprising seven diverse multimodal tasks, utilizing Qwen2.5-VL-7B-Instruct as the base model for continual post-training. The investigation yields two significant findings: (1) When continuously learning on downstream tasks, SFT leads to catastrophic forgetting of previously learned tasks. In contrast, RFT inherently preserves prior knowledge and achieve performance comparable to multi-task training. (2) RFT successfully protects and even enhances the model’s general knowledge on standard benchmarks (e.g., MMMU and MMLU-Pro). Conversely, SFT degrades general model capabilities severely. Further analysis reveals that this stability is not primarily due to explicit mechanisms like KL penalty or chain-of-thought reasoning. Instead, we identify an implicit regularization mechanism inherent to RFT as a key contributing factor. Our theoretical analysis suggests that RFT’s gradient updates are naturally scaled by the reward variance, acting as a data-dependent regularizer that inherently protects previously acquired knowledge. Finally, we propose a rollout-based instance filtering algorithm to enhance the stability and efficiency of RFT. Our comprehensive study demonstrates the superiority of RFT as a robust paradigm for continual post-training.
Nathan also discusses RFT in this Interconnects post.
In RFT, a grader is used to verify outputs, analogous to LLM as a Judge. Hence, it is worth exploring what suite of graders would be useful for many AI-centric Use Cases. John Allard from OpenAI describes them in this X post. Graders may be useful for testing, as well as tuning.
Nathan says that the data used includes a prompt and an answer, so basically Q&A pairs, but it’s not clear if OpenAI allows open-ended questions and answers or if more structure is expected.
He points out that Ai2’s Open Instruct uses a similar approach to RFT for post training. See this paper, TÜLU 3: Pushing Frontiers in Open Language Model Post-Training. His slides include a screen shot of this Ai2 dataset on HuggingFace, which is part of the Tülu 3 release, a dataset containing instruction-following data formatted for use with Ai2’s Open Instruct system, specifically supporting Reinforcement Learning with Verifiable Rewards (RLVR).
OpenAI uses a special LM to extract the answer for reward computation. Nathan cites the example challenge of recognizing that, for example, “.05, 1/20, \frac{1}{20} (LaTex), 5E-02, and 5 x 10^-2, …” all refer to the same value and the answer extractor needs to account for such differences.
Concluding Advice
The talk concludes with the following summary (lightly edited):
- Data is always the most important part of these processes.
- You need your own evaluations.
- Still a lot of under-explored research in fine tuning from instruct models.
- RL fine tuning will open up a lot more domains where specific correctness matters.
- For behavior control, SFT/IFT (supervised/instruction fine tuning) is still your best bet.
- Preference tuning is largely not worth spending time on for now. It requires high effort, it’s a new research topic, and it mostly just delivers style and small performance gains.
-
Nathan spells it finetuning, but we spell it as two words. Often, people hyphenate it: fine-tuning. ↩